Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

AI agent infrastructure becomes easier to understand when you look at real companies already building the layer between AI systems and the outside world.
This article explores what Vercel AI Gateway and Firecrawl reveal about AI agent infrastructure, and why these products matter if you are thinking about the category as a founder or builder.
For the full primer, start with What Is AI Agent Infrastructure?.
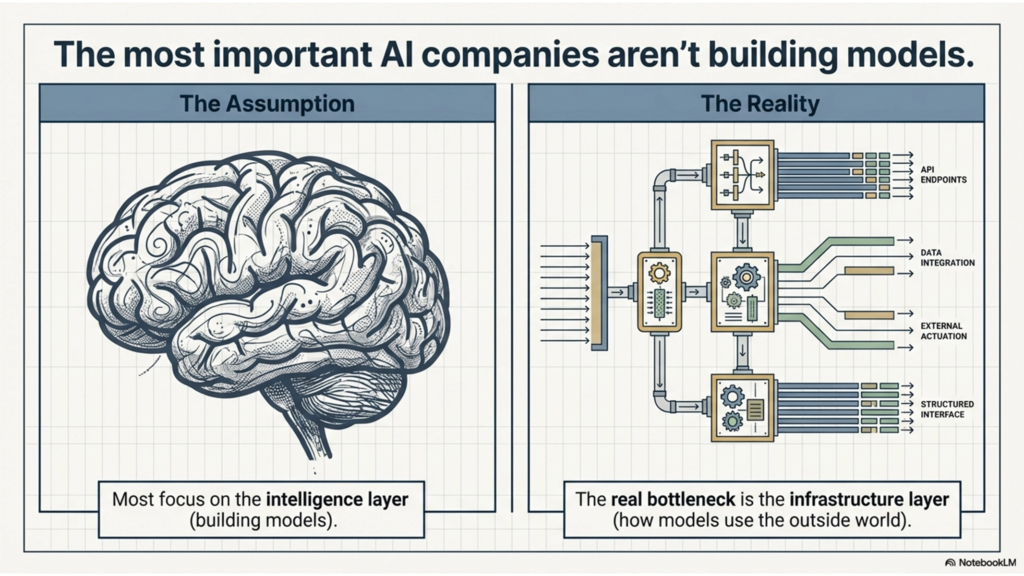
Most people can explain what an AI model is. Far fewer can explain what AI agent infrastructure is.
That gap matters. Some of the most important companies in AI are not building the models themselves. They are building the layers that help AI systems actually use the outside world: models, websites, tools, and data sources. As I’ve been exploring a startup idea around biodata infrastructure for AI agents, I kept coming back to one question: what does a real AI agent infrastructure business actually look like? Two of the clearest benchmarks I found were Vercel AI Gateway and Firecrawl. Vercel describes AI Gateway as a unified API to access hundreds of AI models through a single endpoint, with budgets, usage monitoring, load balancing, and fallbacks. Firecrawl describes itself as a web data API for AI that helps systems search, scrape, crawl, and interact with the web in AI-ready formats.
What struck me was that these companies are not “AI models” at all. They are infrastructure products. Vercel sits between an application and many model providers. Firecrawl sits between an application and the public web. Neither one wins by owning the layer underneath. They win by making that layer easier to use, more reliable, and more programmable. That, to me, is the clearest working definition of AI agent infrastructure: the layer that helps an AI system reliably access the models, tools, data, and actions it needs to do useful work.
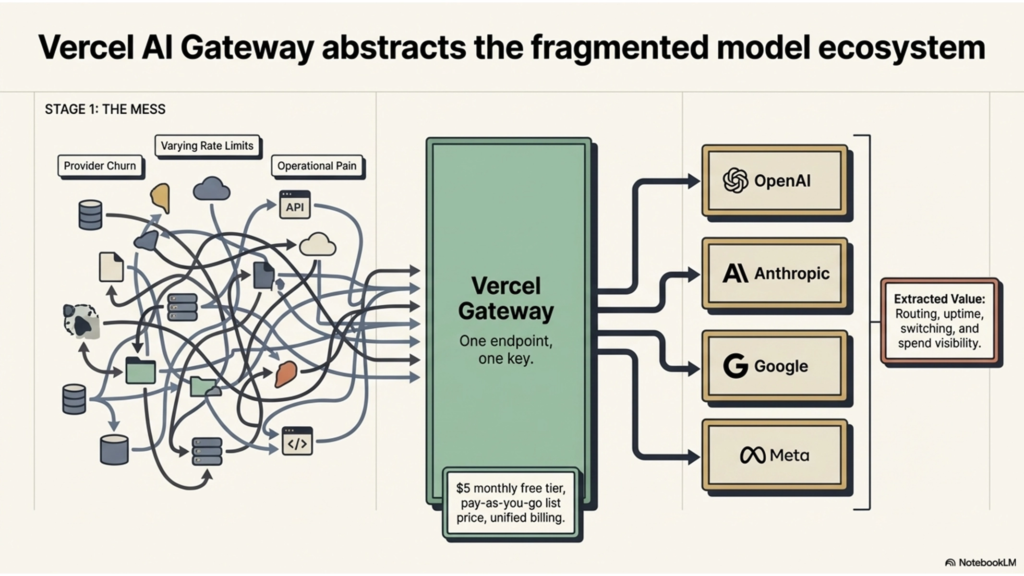
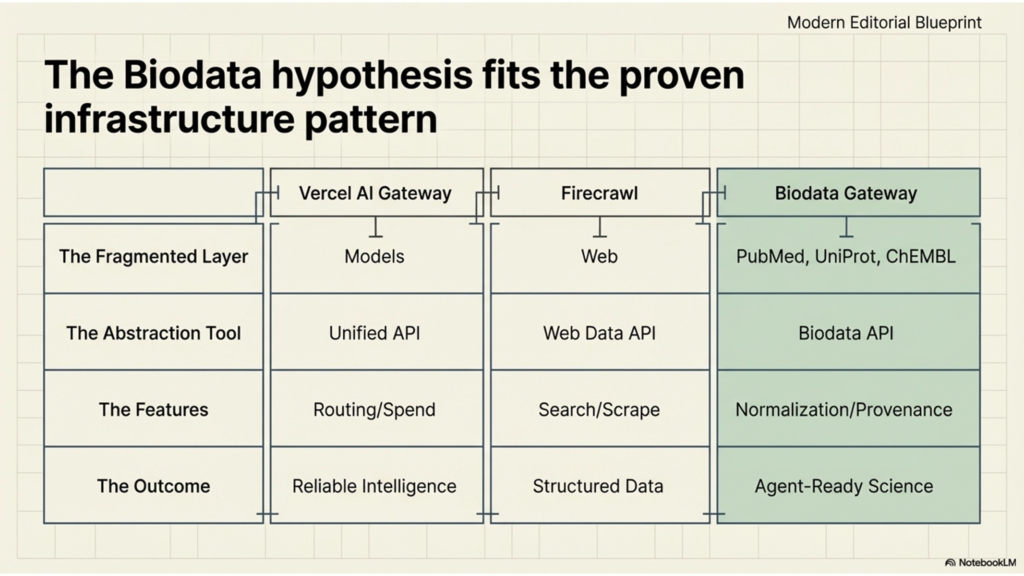
The biggest lesson from Vercel AI Gateway is that a fragmented ecosystem can become an infrastructure business on its own.
Vercel’s product is simple to describe and important to interpret correctly. AI Gateway gives developers one interface for many model providers. The official docs emphasize one endpoint, one key, usage monitoring, budgets, load balancing, and failover behavior, while Vercel’s product page emphasizes unified billing and observability, built-in failovers, and “no markup, just list price.” Its pricing docs say usage is pay-as-you-go with no markups, and Vercel’s knowledge base says there is a $5 monthly free tier that resets every 30 days.
The important part is not the feature checklist. The important part is the business logic. Vercel is not trying to own the intelligence layer. It is monetizing the access and control layer around that intelligence: routing, uptime, switching, and spend visibility. That is a very useful benchmark for any founder thinking about AI agent infrastructure, because it shows that real value can be created simply by becoming the cleanest interface to a fragmented but already valuable ecosystem. Vercel’s own launch post makes that logic explicit by framing AI Gateway around provider churn, rate limits, and the operational pain of working across many model ecosystems.
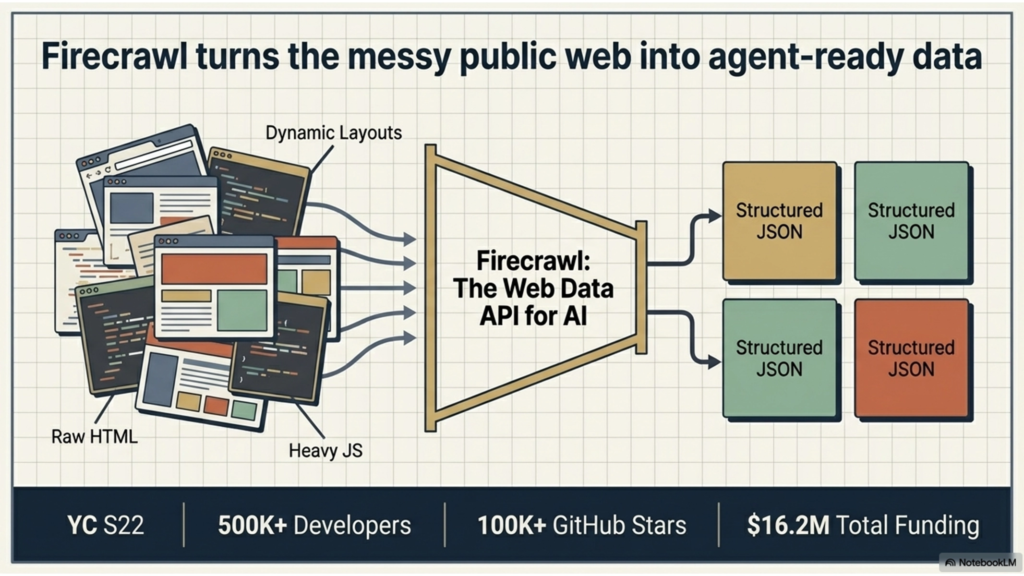
Firecrawl taught me a different version of the same lesson: infrastructure becomes valuable when it makes a messy information layer machine-usable.
The web is full of useful information, but it is not naturally structured for agents. Pages are dynamic. Navigation gets in the way. Content can be buried in inconsistent layouts or hidden behind JavaScript-heavy rendering. Firecrawl’s positioning is direct: it is “the web data API for AI,” built around crawling, scraping, search, and agent workflows. Its docs explain that Firecrawl can search the web, scrape pages, extract structured outputs, and support interaction flows, while its billing docs show that the product is sold as a credit-based infrastructure layer rather than a consumer app.
That matters because Firecrawl is not valuable because it “has the web.” It is valuable because it makes the web usable for downstream AI systems. The company’s About page says its mission is to make web data work for AI “cleanly, scalably, and in real time,” and it describes the web as scattered across millions of domains, locked behind JavaScript, and constantly changing. It also says the company started in 2022 as part of Y Combinator S22 and now reports 500K+ developers signed up, 100K+ GitHub stars, and $16.2M in total funding. Those are company-reported figures, not audited disclosures, but they still show that the market has rewarded a product whose job is to make the web more structured and operationally accessible to AI.
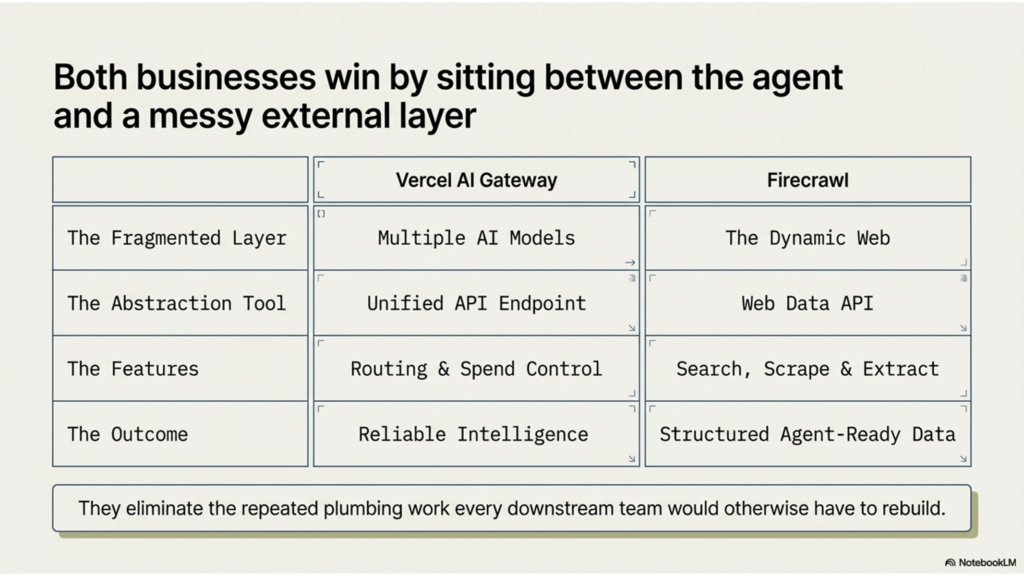
The reason I keep returning to these two companies is not because I want to copy them feature by feature.
It is because they reveal the same pattern. Both businesses win by abstracting fragmentation. Vercel abstracts a fragmented model ecosystem into one interface with routing, failover, and spend control. Firecrawl abstracts a fragmented web ecosystem into one interface with search, scraping, extraction, and interaction. In both cases, the company sits between the agent and a messy external layer, then removes the repeated plumbing work that every downstream team would otherwise have to rebuild for itself.
That pattern has become the core of how I think about AI agent infrastructure. The real product is often not the end-user app. The real product is the interface layer that makes some already-valuable outside system finally usable in production. Once I saw that clearly, my own biodata thesis became much easier to articulate.
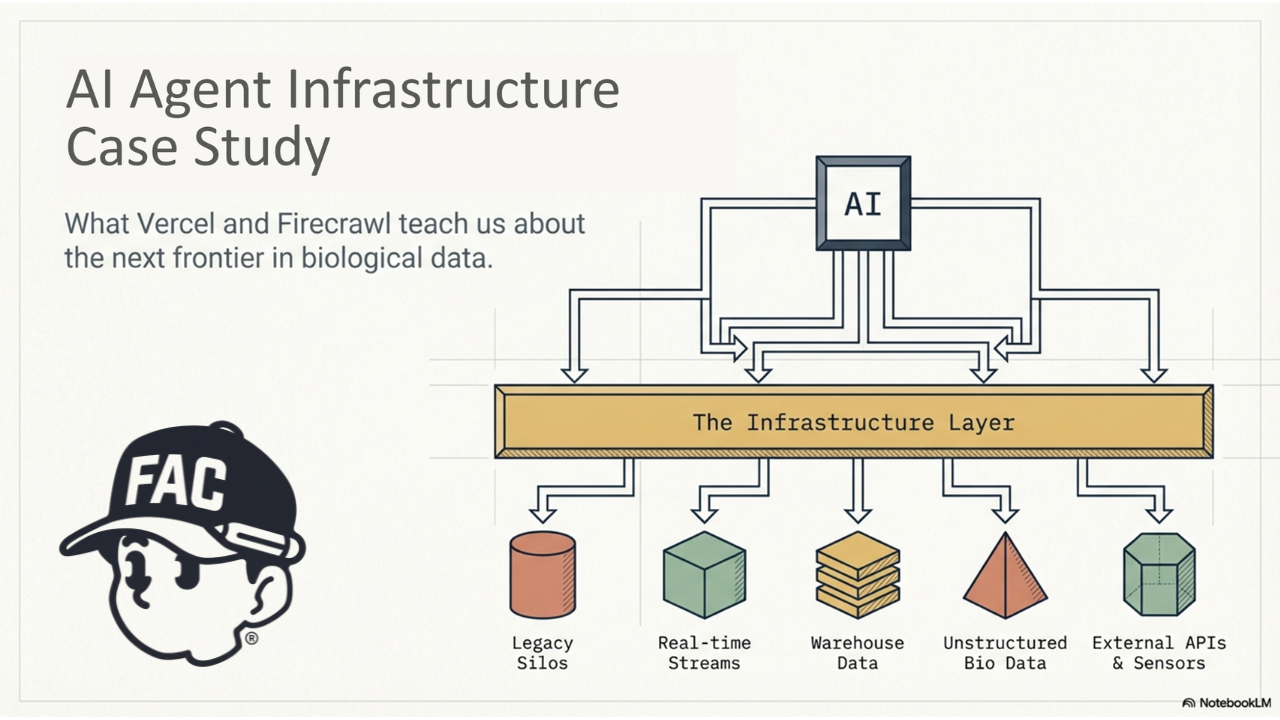
Biological data already lives in high-value systems. But from an agent’s point of view, it is still fragmented.
PubMed says it is a free resource for searching and retrieving biomedical and life sciences literature and contains more than 40 million citations and abstracts. UniProtKB describes itself as the central hub for functional information on proteins. ChEMBL describes itself as a manually curated database of bioactive molecules with drug-like properties that brings together chemical, bioactivity, and genomic data. Each of those resources is valuable on its own. But they do not naturally behave like one clean, agent-ready layer.
That is the part I keep coming back to. Literature lives in one place. Protein knowledge lives in another. Compound and bioactivity data live somewhere else. The schemas differ. The identifiers differ. The access patterns differ. So when an AI agent tries to work across these systems, the hard part is not only reasoning. The hard part is retrieval, normalization, joining, and provenance. That does not automatically prove a startup opportunity. But it does look structurally similar to the kinds of fragmentation problems that Vercel AI Gateway and Firecrawl are solving in other domains.
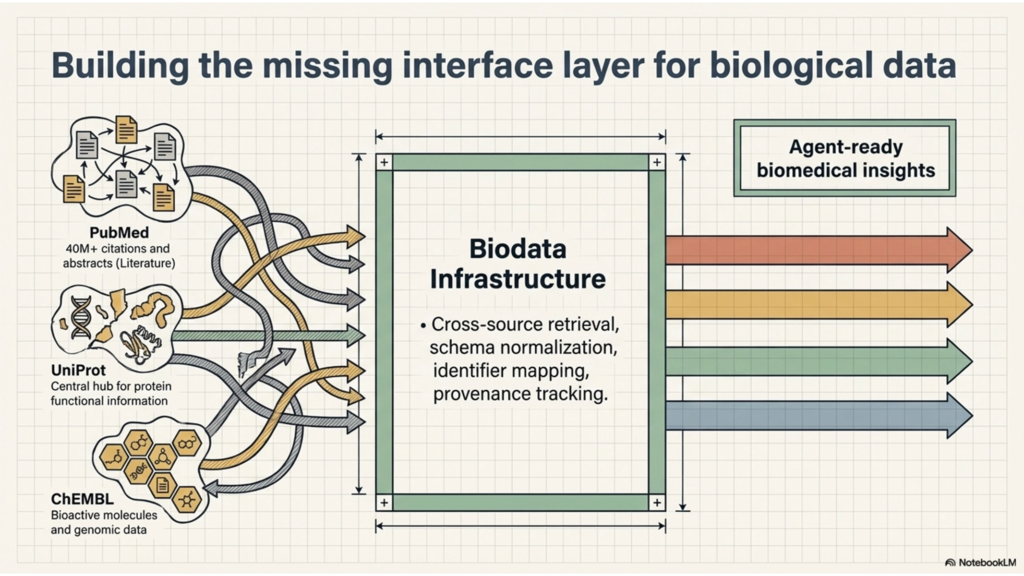
I do not think the opportunity is to replace PubMed, UniProt, ChEMBL, or other core scientific resources.
I think the opportunity may be to build the missing interface layer that helps AI agents use them together.
In practical terms, that could mean a system that handles cross-source retrieval, schema and identifier normalization, provenance tracking, and agent-ready outputs instead of forcing every team to build brittle integrations from scratch. I still see that as a hypothesis, not a conclusion. It needs real workflow validation, real users, and real willingness to pay. But benchmarking Vercel AI Gateway and Firecrawl gave me a much clearer lens: if model access benefited from a gateway layer, and web access benefited from a structured data layer, then it is reasonable to ask whether biological data may also need its own dedicated infrastructure layer for AI agents.
What I learned from studying Vercel AI Gateway and Firecrawl is simple: AI agent infrastructure becomes real when it turns a fragmented external layer into one reliable interface.
Vercel does that for model access. Firecrawl does that for web access. As a founder exploring biodata infrastructure for AI agents, I think the same pattern may apply to biological data. The most interesting infrastructure businesses in AI may not be the ones that build yet another model. They may be the ones that make high-value but fragmented systems finally usable for agents. That is the opportunity I’m trying to understand better, and biodata may be one of the clearest layers still waiting for that abstraction.
The model wars are still on. But this week, the real battleground shifted to deployment. June 1, 2026…
Weekly Briefing The Big Four bet 750,000 seats on Claude. A Fields Medalist says GPT did PhD-level math…
Most brands know they should be listening to what people say online. Very few actually do it well.…