Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


One API key, one response format, 27 platforms. Here is what developers are actually shipping with it.

I built SocialCrawl because I kept hitting the same wall. I was an AI transformation consultant, and every project that needed social data turned into a three-month integration nightmare. TikTok returns follower_count. Instagram calls it followers_count. YouTube uses subscriberCount. Multiply that inconsistency across 27 platforms and 133 endpoints, and you start to understand why most teams give up before they ship anything useful.
SocialCrawl normalizes all of it into one schema. One API key. One response format. Computed fields like engagement_rate and estimated_reach arrive pre-calculated on every response, so your application logic stays simple.

The most common first project. You want to know what people are saying about your brand, product, or competitor across Reddit, X, YouTube, TikTok, and Threads. Without a unified API, that means five separate integrations, five auth flows, five different response parsers.
With SocialCrawl, the entire query loop looks like this:
const platforms = ["reddit", "twitter", "youtube", "tiktok", "threads"];
const results = await Promise.all(
platforms.map((p) =>
fetch(`https://api.socialcrawl.dev/v1/${p}/search?query=your-brand`, {
headers: { "x-api-key": process.env.SOCIALCRAWL_KEY },
}).then((r) => r.json())
)
);
// Every platform returns the same fields
const mentions = results.flatMap((r) =>
r.data.map((post) => ({
platform: post.platform,
text: post.content.text,
sentiment: post.metadata.content_category,
engagement: post.engagement.engagement_rate,
url: post.content.url,
}))
);Five platforms. One parser. You could wire this into a Next.js dashboard in an afternoon. The content_category and engagement_rate fields arrive ready to use, so you skip the entire analytics pipeline most teams spend weeks building.

This is the use case that started SocialCrawl. I wanted an AI agent that could answer questions like “What do developers think about Cursor vs VS Code?” by searching real conversations, not summarizing SEO blog posts.
SocialCrawl ships an MCP server that plugs directly into Claude, Cursor, Windsurf, or any MCP-compatible client. Five tools handle everything:
socialcrawl_list_platforms discovers what is availablesocialcrawl_list_endpoints shows parameters and credit costssocialcrawl_request executes any API call with local validationsocialcrawl_check_balance monitors creditssocialcrawl_get_docs pulls documentation by topicThe agent validates every request locally before making the API call. If a parameter is wrong, it tells the agent exactly how to fix it, without burning a single credit.
Your AI agent can search Reddit threads, pull YouTube comments, scan Hacker News discussions, and cite the actual source URL for every claim it makes.
Configuration is one JSON block:
{
"mcpServers": {
"socialcrawl": {
"command": "npx",
"args": ["-y", "socialcrawl-mcp"],
"env": { "SOCIALCRAWL_API_KEY": "sc_your_key_here" }
}
}
}That is all it takes to give your agent access to 27 platforms worth of live social data.

Brands spend millions on influencer partnerships and still get burned by fake followers and inflated engagement. The problem is that checking an influencer’s real performance means logging into six different platforms and doing math by hand.
SocialCrawl computes engagement_rate and estimated_reach on every profile response. Pull an influencer’s data across TikTok, Instagram, YouTube, and LinkedIn in four parallel requests, and you have a complete cross-platform scorecard in under two seconds.
import asyncio, aiohttp
async def vet_influencer(handle):
platforms = ["tiktok", "instagram", "youtube", "linkedin"]
async with aiohttp.ClientSession() as session:
tasks = [
session.get(
f"https://api.socialcrawl.dev/v1/{p}/profile?handle={handle}",
headers={"x-api-key": API_KEY}
)
for p in platforms
]
responses = await asyncio.gather(*tasks)
profiles = [await r.json() for r in responses]
return {
p["platform"]: {
"followers": p["data"]["author"]["followers"],
"engagement_rate": p["data"]["engagement"]["engagement_rate"],
"estimated_reach": p["data"]["engagement"]["estimated_reach"],
}
for p in profiles
if p["success"]
}If someone has 500K followers on Instagram but a 0.2% engagement rate, and 50K followers on TikTok with a 6.8% engagement rate, you know where the real audience is. That signal used to take an analyst a full day to produce. Now it takes one API call per platform.
Trends move faster than most teams can track them. By the time a topic shows up in Google Trends, the conversation on Reddit and TikTok has already moved on.
SocialCrawl’s search and trending endpoints let you build a trend detection system that scans conversations as they happen. Query the same keyword across multiple platforms every hour, compare engagement velocity, and you can spot breakout topics 24 to 48 hours before they peak on traditional search.
The computed content_category field lets you filter noise automatically: only surface posts categorized as “tech” or “finance” or “gaming” depending on what your audience cares about, without building your own classifier.
Pair this with a simple time-series store (even a SQLite database works), and you have a trend radar that most marketing teams would pay five figures a year for.
Product teams always want to know what content their competitors publish, how it performs, and which topics get the most engagement. The manual version of this is someone scrolling through competitor profiles every Monday morning. It does not scale.
With SocialCrawl, you can pull a competitor’s recent posts across every platform they are active on, rank them by engagement_rate, and flag any post that outperforms their average. Run this as a daily cron job, pipe the results into Slack or email, and your team gets a briefing every morning without anyone lifting a finger.
The response includes language detection and content_category classification, so you can also track what topics your competitors are leaning into across different markets and audiences.

This is the mirror image of the competitor tracker. Connect your own handles, pull post-level analytics across every platform you publish on, and build a single view of what is working.
Most social media tools charge $50 to $300 per month for this. With SocialCrawl’s credit-based pricing, you can build a custom version that fits your exact workflow for a fraction of the cost. The Growth plan at £49 per month gives you 25,000 credits. That is 25,000 API calls, enough to track dozens of accounts across multiple platforms with daily granularity.
The real value is in the unified schema. When every platform returns the same fields, you can answer questions like “Which platform gives us the best engagement rate per post?” with a simple SQL query instead of a custom ETL pipeline for each network.
These are the six projects I see developers building most often. But the API covers 133 endpoints across 27 platforms, so the surface area is much larger than what I listed here. People have built podcast research tools, job market monitors using LinkedIn data, betting signal analyzers using Polymarket endpoints, and code repository trend trackers through the GitHub integration.
The free tier gives you 100 credits to test the schema before committing. No credit card. No sales call. Just sign up at socialcrawl.dev, grab an API key, and start building.
If you build something interesting, I want to see it.
If you've ever tried to pull data from Reddit, then YouTube, then TikTok, then X, each with its…
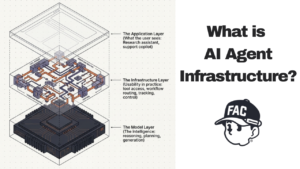
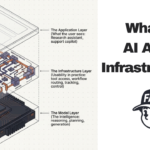
Learn what AI agent infrastructure is, why it matters, and which tools help AI agents connect to models,…
The model wars are still on. But this week, the real battleground shifted to deployment. June 1, 2026…