Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124



Generative AI has stopped being a single conversation about chatbots. It’s now a competitive field of specialist models, each tuned for a particular kind of work. In 2026, the question isn’t whether to use these systems. It’s which one to organise your workflow around.
A generative AI model is an artificial intelligence system trained to create new content, including text, images, code, audio, and video, by learning statistical patterns from very large datasets. Unlike traditional machine learning models that classify or predict, generative models produce original outputs that did not exist in their training data.
It includes large language models such as GPT-5.5 and Claude Opus 4.8, multimodal systems such as Google’s Gemini 3.1 Pro, diffusion-based image generators such as Stable Diffusion and Midjourney v7, and video models such as OpenAI’s Sora 2 and Google’s Veo 3. According to Pluralsight’s 2026 model survey, generative AI now falls into four distinct specialisations: general-purpose language models, agentic coding models, creative media models, and scientific discovery models. The era of one model trying to do everything is over.
Architecturally, most of these systems remain transformer-based, but the interesting design work has moved elsewhere. Mixture-of-Experts (MoE) architectures, used by Gemini 2.5 Pro and Moonshot’s Kimi K2, route each request to a small subset of specialist sub-networks rather than activating every parameter. The result is performance comparable to much larger dense models at a fraction of the inference cost.
The numbers explain why every major software vendor has restructured around generative AI. The global generative AI market is projected to reach $83.3 billion in 2026, according to Global Market Insights, with broader estimates that include platforms and services pushing as high as $140 billion. North America holds an estimated 45.1% of that market.
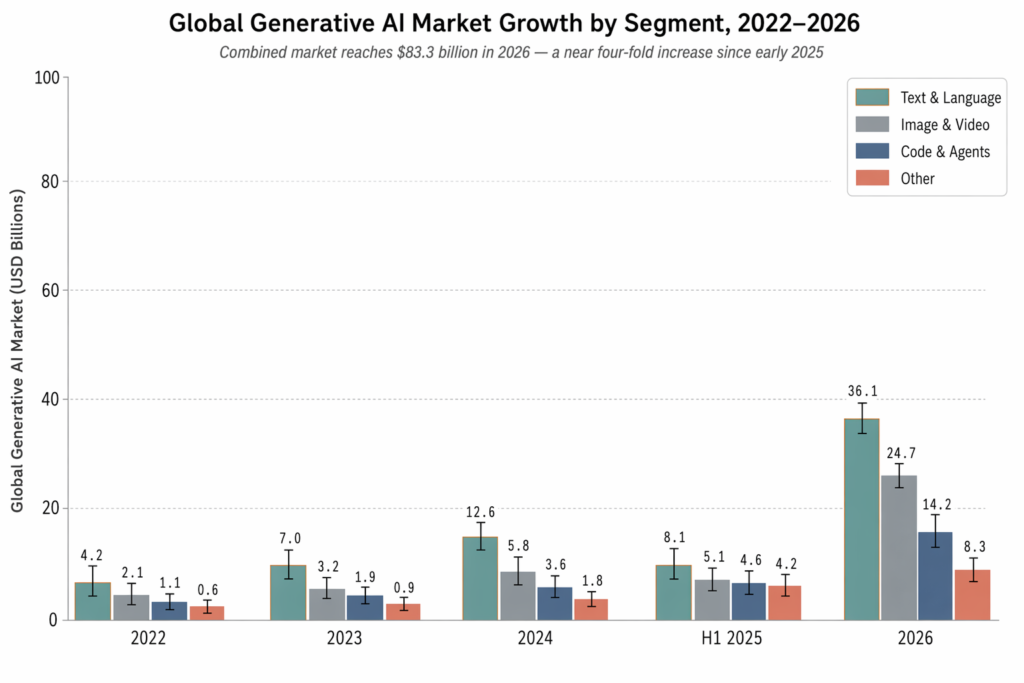
The growth rate matters more than the headline figure. The same Global Market Insights data puts the market at roughly $22 billion in early 2025, meaning it’s multiplied by close to four in under two years. McKinsey’s 2025 State of AI report found that 88% of organisations now use AI in at least one business function, with 71% specifically using generative AI rather than older predictive systems. Budgets that used to fund pilots are now funding production deployments, and procurement teams have started asking hard questions about model selection, vendor lock-in, and total cost of inference.
The headline leaders are familiar names with very recent releases. OpenAI’s GPT-5.5, launched in April 2026, achieved 82.7% on Terminal-Bench 2.0 and 58.6% on SWE-Bench Pro, with the company describing it as a unified system that routes each request to the right internal sub-model. Anthropic’s Claude Opus 4.8, released on 28 May 2026, reached 84% on Online-Mind2Web and beat GPT-5.5 on the Super-Agent benchmark, as detailed in Anthropic’s launch announcement. Google’s Gemini 3.1 Pro, released in preview in February 2026, topped 13 of 16 benchmarks at launch and reached 94.3% on GPQA Diamond, the gold standard for expert-level multidisciplinary reasoning.
Below the headline three sits a deeper bench than most readers realise. Meta’s Llama 4 Scout is the open-source surprise of the year, shipping with a 10 million token context window, several times larger than any closed competitor. xAI’s Grok 4.3 has carved out a niche around real-time data access and conversational use. China’s labs are no longer also-rans: Moonshot AI’s Kimi K2 Thinking, a trillion-parameter MoE model, has been downloaded 397,536 times on HuggingFace, and DeepSeek’s v3.2 picked up 67,173 downloads within fifteen days of release, with particular strength in mathematics and cost efficiency.
For specialist work, the picture splits further. Microsoft’s Phi-4 competes with models a hundred times its size on selected benchmarks, the standard proof point when arguing that parameter count is no longer everything. For creative media, Midjourney v7 and Stable Diffusion dominate images, whilst Sora 2, Veo 3, and Runway Gen-3 lead text-to-video. The State of AI Report 2025 noted that the performance gap between US laboratories and the rest of the world has nearly vanished, with French, Chinese, and European labs now leading in specific domains.
The three frontier models are often presented as interchangeable. They are not.
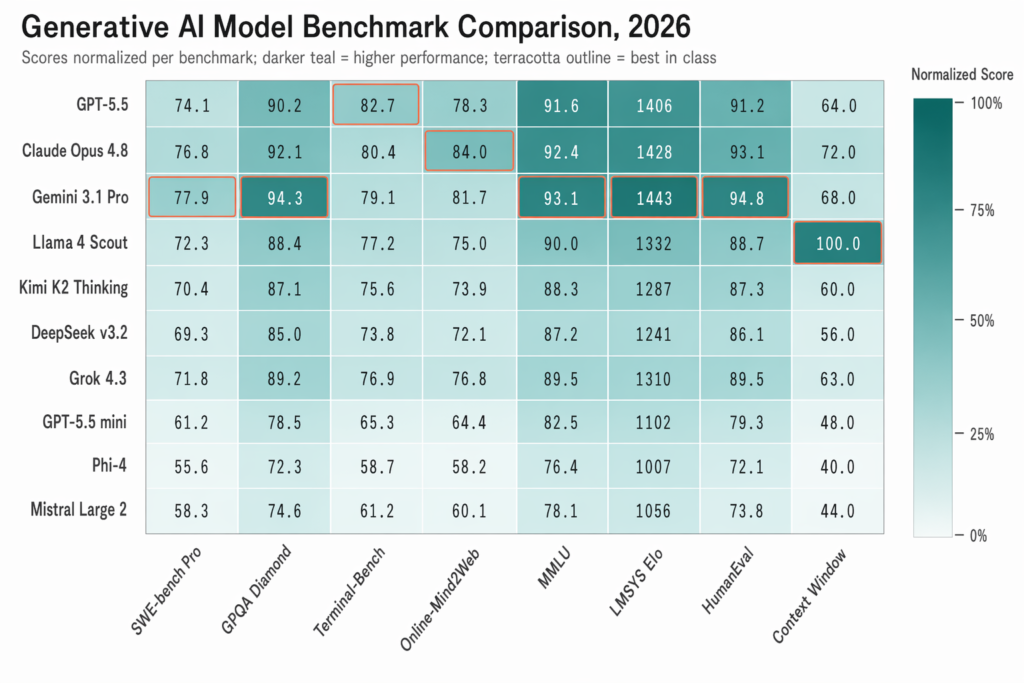
OpenAI’s GPT-5.5, introduced in OpenAI’s announcement post, is the breadth and ecosystem play. It runs on the largest deployment surface, integrates into Microsoft Copilot, and leads on terminal and DevOps benchmarks. The unified routing system scales compute to the difficulty of each request. GPT-5.4 Pro currently sits at Elo 1502 on the LMSYS Chatbot Arena, holding the top human preference ranking.
Claude Opus 4.8 is the model to reach for when reasoning and software engineering matter more than ecosystem breadth. The earlier Opus 4.7 hit 87.6% on SWE-bench Verified and 94.2% on GPQA Diamond, and Opus 4.8 pushed agentic web benchmarks further with that 84% Online-Mind2Web score. Anthropic’s Constitutional AI safety architecture makes it the preferred choice for regulated industries where audit trails and predictable behaviour matter.
Gemini 3.1 Pro is the price-to-performance leader for multimodal work. Pricing sits at $2.00 per million input tokens, undercutting both rivals at the top end, whilst Gemini 2.5 Flash handles high-volume production traffic at a fraction of the cost. The model processes text, image, audio, and video natively, and the 1 million token context window puts it level with Claude on long-document analysis.
A useful comparison from Pluralsight’s research: Claude 4.5 Sonnet costs around $0.56 per task at a 70.6% completion rate on agentic benchmarks; GPT-5 mini costs roughly $0.04 per task at 59.8%. The right answer depends entirely on how much a mistake costs you.
The short answer is yes, and the gap is narrower than industry marketing suggests.
Meta’s Llama 4 is the most consequential open-weight release of the cycle. The Scout variant ships with a 10 million token context window, which means a single inference can ingest an entire mid-sized codebase, a stack of legal contracts, or a full research corpus. No closed model offers anything close. For organisations with data sovereignty requirements, the option to self-host a model of this calibre changes the procurement conversation entirely.
Outside Meta, the open ecosystem is healthier than at any point since transformers became dominant. DeepSeek v3.2 sits near the top of mathematics benchmarks at a tiny fraction of GPT-5.5’s running cost. Kimi K2 Thinking from Moonshot AI has reached an LMArena Elo of 1380, well within the top ten. Mistral Large 2, from the French laboratory Mistral AI, offers strong open-weight performance with European data residency, a meaningful selling point for organisations operating under GDPR or the AI Act.
The trade-off hasn’t vanished. Closed commercial models still lead the very top benchmarks, often by a few percentage points, and require no infrastructure investment. For experimental work, prototyping, and consumer-facing applications, the closed APIs remain the path of least resistance. Open-weight models win on enterprise self-hosting, regulated deployments, and workloads large enough that API costs start to dominate the budget.
Strip away the demos, and real production use cases cluster into a handful of categories that organisations are spending real money on.
Customer support automation remains the highest-volume deployment. GPT-5, Claude 4.5 Sonnet, and Gemini 2.5 Flash handle conversational queues at scale, with Gemini 2.5 Flash now the default choice for high-throughput traffic thanks to its price-performance balance and low latency. In the UK, Octopus Energy has been a notable early mover, routing a significant proportion of customer emails through AI systems before human review.
Agentic coding is the use case that has moved fastest in the last twelve months. The new generation of coding agents, led by Claude Opus 4.8 and GPT-5.5 Codex, can take a task description, read a codebase, write the change, run tests, and fix their own bugs without human intervention. Claude 4.5 Sonnet resolves over 70.6% of real GitHub issues on SWE-bench Verified, a number that would have been considered fanciful eighteen months ago.

Content and marketing teams use GPT-5 and Claude Opus 4.7 for first-draft articles, ad copy, and customer emails. Multimodal research workloads exploit the large context windows in Gemini 2.5 Pro and Llama 4 Scout to process entire legal bundles or research libraries in a single prompt. In scientific work, Gemini 3.1 Pro and OpenAI’s science-tuned variants are being paired with London-based Google DeepMind’s AlphaFold 3 for drug discovery and protein structure prediction.
The common pattern across all of these is augmentation, not replacement. A small team now does work that previously required a much larger one.
The technology has matured, but its limitations haven’t gone away.
The first misconception is that any single model is the best. The 2026 landscape has specialist leaders, not a single champion. Claude Opus 4.8 leads agentic software engineering. Gemini 3.1 Pro leads multimodal reasoning. GPT-5.5 leads on terminal and DevOps benchmarks. Anyone telling you there’s a universal winner is selling something.
The second misconception is that bigger means better. Microsoft’s Phi-4, announced in December 2024, achieves competitive scores against models a hundred times its size. Architecture innovations such as MoE routing, Constitutional AI, and test-time compute now matter far more than raw parameter count.
The third misconception is that these systems understand content the way humans do. They don’t. A study covered in r/technology reported that top models including GPT-4o, Claude 3.5, and Gemini 2.5 completely failed the classic Stroop psychological attention test, a result that highlighted the gap between statistical pattern matching and genuine cognitive reasoning. Generative models produce plausible outputs based on training data, not understanding.
Finally, the fear that AI will imminently replace all software developers doesn’t match the evidence. Even Claude Opus 4.8, at 84% on Online-Mind2Web, fails on a meaningful proportion of tasks and needs human oversight on anything consequential. Developers who use these tools are dramatically more productive, but human judgement on architecture, business context, and trade-offs remains essential.
The right model depends almost entirely on the task in front of you.
For software development and agentic coding, Claude Opus 4.8 or GPT-5.5 Codex are the defaults. For multimodal analysis involving images, audio, or video alongside text, Gemini 3.1 Pro is the strongest choice. For budget-constrained production traffic, GPT-5 mini at roughly $0.04 per task or Gemini 2.5 Flash will both outperform their headline rivals on cost. For data privacy, regulated industries, or anywhere self-hosting is required, Llama 4 Scout is the obvious starting point, with DeepSeek v3.2, Mistral Large 2, and Kimi K2 as credible alternatives. For creative media, the choice splits by medium: Midjourney v7 or Stable Diffusion for images, Sora 2, Veo 3, or Runway Gen-3 for video.
A practical sequence works well. Identify the dominant task type, set a budget per inference and ignore models that exceed it, then run the shortlist against ten representative examples from your own data rather than generic benchmarks. Check the governance and data residency story, especially in regulated sectors. Plan for the model to change within six months, because the release cadence here is faster than any procurement cycle. Build your stack so that swapping the underlying model is a configuration change rather than a rewrite. That’s the most valuable architectural decision you can make today.
What is a generative AI model?
A generative AI model is a type of artificial intelligence trained to create new content, including text, images, code, audio, or video, by learning statistical patterns from vast training datasets. Unlike traditional AI models that classify or predict, generative models produce novel outputs. Examples include GPT-5 (text), Midjourney (images), and Sora 2 (video).
What is the best generative AI model in 2026?
There is no single best model. Performance depends on the task. For agentic coding, Claude Opus 4.8 leads on SWE-bench. For multimodal reasoning, Gemini 3.1 Pro tops 13 of 16 benchmarks. For general-purpose use and ecosystem breadth, GPT-5.5 from OpenAI is the market leader. For open-source self-hosting, Llama 4 Scout from Meta is the top choice, thanks to its 10 million token context window.
What is a context window and why does it matter?
A context window is the maximum amount of text, measured in tokens, that a model can process in a single interaction. Larger context windows allow models to analyse entire codebases, lengthy legal documents, or full books at once. In 2026, leading commercial models offer 1 million tokens (Claude, Gemini), whilst Meta’s Llama 4 Scout extends this to an unprecedented 10 million tokens.
Are open-source generative AI models as good as commercial ones?
Open-source models have closed the gap dramatically. Meta’s Llama 4, DeepSeek v3.2, Mistral, and Kimi K2 now compete with commercial frontrunners on many benchmarks. They may lag slightly on the very top scores, but they offer no API costs, full data privacy, and self-hosting flexibility, which makes them compelling for enterprises with sovereignty requirements.
Is generative AI safe to use for business?
Generative AI is widely used in business but carries real risks, including hallucinations (plausible but incorrect outputs), data privacy concerns, bias, and misuse potential. Models such as Claude (Anthropic) are built with Constitutional AI safety frameworks to reduce harmful outputs. For enterprise deployment, best practice involves output verification, data anonymisation before sending to external APIs, and human review for high-stakes decisions.
GPT-5.6 solves a 50-year math problem. An AI agent raises $100 million. And Congress wants to know who…
Ownership, regulation, drug discovery, infrastructure. Four stories that prove AI is no longer just a technology question. By Woosub…
A $60 billion acquisition, a shadow-deployed model, a nudifier ban, and $293 million into agent guardrails. The industry…